| Table of Contents Previous | Next |
Apache Server Survival Guide |
If there's one thing there is never enough of, it's speed. Speedy delivery of your content is one way to enhance your site's appeal. Slow sites usually get clicked away because computers are good at eliminating patience from their users. A computer will never be fast enough. As a webmaster, it is your responsibility to maintain and tune your system to meet the performance needs of your users. Many of the things you can do will depend on the size of your budget. Dream systems and high-speed networks are available, but at a premium.
Performance tuning is an art. Where you spend money in terms of hardware can make a big difference in the cost and performance of your site. Performance enhancements also raise the initial cost of hardware, which gets cheaper and more powerful everyday. Some performance tuning issues don't cost anything; they relate more to the design of your site and how users navigate it. Other issues involve tuning your software so that your system can run optimally. Another option involves the organization of your systems; arranging your network in a certain way can provide certain benefits that enhance the overall performance of your site.
Here are the four performance issues you'll explore in this chapter:
If you are willing to spend the time, fine-tuning your kernel can make all the difference in the world in terms of performance. However, you should be very careful to have a bootable kernel available in case you manage to kill the system. The best advice regarding kernel configuration is don't do it unless you know exactly what you're doing.
Other than tuning your kernel and server software, there's only so much you can do to enhance the performance of your server. Performance is really an input/output issue, and it affects all aspects of your system and network. Think of your system as plumbing: The bigger the pipes, the faster the drain. No matter how much water you have, it can only drain so quickly. To make matters worse, ultimate transfer rates are determined by the smallest segment of the pipe, no matter how fast your server is.
All performance issues are interrelated. When some subsystems get maxed out before others, a cascading effect usually occurs; a system with insufficient memory will swap, slowing the processing speed and the network I/O. A server with really fast networking hardware but slow disk access won't be able to match its networking subsystem, so the networking hardware's potential is never realized.
Your Web server's performance depends on the following hardware and associated software subsystems:
Processing speed is how fast your computer can process a request in terms of CPU usage. The Web doesn't create a very strenuous demand on most capable systems unless they are subjected to a very intense load. A Pentium box running Linux can swamp a DS-1 (T-1) line way before the hardware even feels it. Chances are that the networking bottlenecks are going to be noticed. Assuming that traffic increases proportionally to the size of your wide area network (WAN) interface, bigger WAN interfaces require more processing to handle requests.
Distributed Web servers are a way of increasing the performance of your Web site when the bottleneck is load on your Web server. Assuming that your gateway bandwidth is greater than the performance of your computer, you may be able to obtain better performance by evenly distributing the load over several servers.
Instead of having all traffic directed to one system, the load is distributed as evenly as possible across an array of servers (mirrors). This allows heavy traffic sites to maximize the performance of their servers and at the same time reduce the delays associated with slow server response due to an overly loaded host.
The technique I will describe is a Domain Name System (DNS) technique that provides a different server for each new connection. When a client contacts DNS to find the IP address of the server, it will answer with a rotating list of IPs so each request will be replied with a different machine in a round-robin fashion. This allows for a more equal load distribution across the number of hosts you provide because each connection will be served by a different host.
For moderate traffic sites, a two-server machine will offer better performance at peak times. Some busy sites, such as www.yahoo.com, have more than nine Web servers serving requests for their main entry point, http://www.yahoo.com.
As far as users are concerned, there's only one machine, www.yahoo.com. However, the distribution helps tremendously because sites such as www.yahoo.com have very intense computational CGI loads. This positively affects responsiveness of the site.
The technique for distribution is almost trivial to implement. And while it is not guaranteed to be supported in the future because, according to the DNS Requests For Comments (RFCs) papers, this round-robin behavior is not defined. This solution works, and it works well. I believe many sites use this feature, and eventually the Berkeley Internet Name Domain (BIND) system release and associated RFCs will address it in a more formal way. For now, let's hope that the developers of BIND don't fix what isn't broken.
Here's a snippet of a simple db.file that implements distribution of its Web server over three different hosts (for information about setting up DNS, see Appendix D, "DNS and BIND Primer"):
www IN CNAME www1.domain.COM. IN CNAME www2.domain.COM. IN CNAME www3.domain.COM. www1 IN A 4.3.2.1 www2 IN A 4.3.2.2 www3 IN A 4.3.2.3
This simple setup would rotate the three addresses. However, if you observed closely and are aware of DNS caching, you'll know that this would only work for new DNS requests. Remember that DNS requests are cached for the duration of the Time To Live (TTL) delay. This delay is usually set to 24 hours (86,400 seconds). In order to avoid this caching, you'll most certainly want to set the TTL anywhere between 180-600 seconds (3-10 minutes). This will force some clients to re-request the IP of your server when the TTL has expired, forcing requests to be more evenly balanced across machines. On the downside, this setting creates a bigger DNS load. But any DNS load is minor in contrast to the volume of data that your server will move around.
It is worth mentioning that many Web browsers (Netscape included) cache DNS address/name mappings internally and disregard TTL altogether. This means that one client, once he begins accessing a given server, will stick with that particular address until the next time it is restarted. However, the distribution effect is still achieved over many different clients, and that is what is important.
For busier sites, you could implement multilevel rotations by specifying a setting such as the following:
www IN CNAME www1.AccessLink.COM. IN CNAME www2.AccessLink.COM. IN CNAME www3.AccessLink.COM. www1 IN A 4.3.2.1 IN A 4.3.2.11 IN A 4.3.2.21 www2 IN A 4.3.2.2 IN A 4.3.2.12 IN A 4.3.2.22 www3 IN A 4.3.2.3 IN A 4.3.2.13 IN A 4.3.2.23
This setup would require nine separate servers and would implement a two-level rotation. The first rotation occurs at the CNAME level and the second at each A (Alias) level.
While any server rotation technique may only be useful on heavily loaded sites, it is very useful when combined with multihomed Web servers. By making distributed servers multihomed, you have the ability to build a more reliable Web service. Not only would the load be distributed between machines, but in case of a failure, one of the mirror servers could take over transparently. Even if the system administrator didn't become aware of the problem immediately, the virtual (or real) sites would continue to operate by providing uninterrupted service. Naturally, this robustness is equally valuable for distributed single-homed sites. But because the likelihood of a server failure is greater on a multihomed host (Murphy's Law), preparing for such a disaster and implementing a fault-tolerant service may be the best tool to use to avoid a server outage.
Because Web servers are RAM hogs, RAM is the one hardware addition that will pay off big. RAM helps every part of your system. The more RAM you have, the better your system works.
How much RAM is enough? There isn't a single administrator who wouldn't love to have 256MB of RAM on his server. So it depends. If you have a RISC machine, you'll probably need double the memory of an equivalent CISC box. Some smaller sites with limited traffic can do very well with under 16MB of RAM. 32MB is probably a good starting point. You can then start monitoring you server for bottlenecks and add RAM as needed.
One easy way to test for memory bottlenecks is to use the vmstat (or vm_stat) command, which will display virtual memory statistics for your system. You want to watch the number of pageins and pageouts, which tell you how much swapping your system is doing. If it gets so bad that you can hear the machine constantly swapping (the disk making constant accesses), you are in trouble. Go buy some RAM.
One way to reduce the amount of RAM your system consumes is to limit the number of services that are running on the server. If your Web server is a busy one, and you are also running a myriad of other services such as DNS, NFS, NNTP, SMTP, shell accounts, and FTP, your system will have to divide its resources between those tasks. Running only the necessary services on your server box will allow you to maximize your resources. If the machine is not a mail server, you can probably have sendmail, the mail daemon, run under inetd. Do the same for any other services that you may want available but that are non-essential. You may want to consider using separate boxes to provide all the other services, thus freeing resources for the Web server to do its thing.
If you have a Web server that makes heavy use of CGI, the performance of your server will decrease. One way to alleviate this problem is to recode the CGI program to a compiled language instead of an interpreted script. Both programs do the same thing, but the speed and efficiency of a compiled binary can be several orders of magnitude greater. The section in this chapter titled, "CGI Program Tuning," discusses the CGI impact in more detail.
Disk speed is probably one of the first bottlenecks you'll run into. The speed of a modern hard disk does not even begin to match the capacity of some of the most common processors. Disks are the turtles of the system, and Web servers demand a lot from them. After all, all requests end up generating a disk access of some sort. The faster your processor is able to read the disk and process it, the faster it can go handle another request.
Although purchasing a faster disk can help a lot, adding a dedicated disk subsystem to handle swapping (your server should not really swap anyway), log files, and data files will help even more. For real performance, a RAID solution may be the only way to go for data storage in a heavily loaded server.
The concept of RAID was developed at the University of California at Berkeley in 1987 by Patterson, Gibson, and Katz in a paper titled "A Case for Redundant Arrays of Inexpensive Disks (RAID)."
The idea behind RAID is to combine several small, inexpensive disks into a battery of disk drives, yielding performance exceeding that of a Single Large Expensive Drive (SLED). All disks in the array appear as a single logical storage unit, or a single disk, to the computer. Because the disk controller(s) and the host processor are able to request or initiate read or write operations more quickly than any disk can satisfy them, having multiple disks allows some degree of parallelism and concurrency between transactions. Another important consideration is that by spreading a single data file on various disks (striping), all disks can work concurrently. This provides better load balancing than would be otherwise possible. Without this improved load balancing, some disks would end up doing most of the work. By distributing the load, requests can be fulfilled more quickly because each disk has less to do. This allows each drive to work on a different read/write operation and maximize the number of simultaneous I/Os that the array can perform, thus increasing the transfer rate.
Although RAID offers a big enhancement in performance, your mileage may vary depending on the RAID configuration implemented. Also, it is important to note that using more hardware increases the likelihood of a failure; given that data is spread across multiple disks, a drive failure could be catastrophic. RAID can achieve increased reliability by mirroring data on duplicate drives or by using error-recovery technology that allows on-the-fly data reconstruction. However, this redundancy comes with a performance trade-off.
RAID systems usually allow for the hot-swapping of drive components without having to halt the system. On replacement, most RAID implementations reconstruct data that was stored on the failed drive, allowing the array to continue operation at optimal speeds. On the current commercial RAID offerings, an array will tolerate the loss of a single drive, but multiple drive failures in the array will destroy data. Most catastrophic array failures are due to the system administrator's lack of awareness of a drive going bad ; failure of a second drive is what causes the devastating consequences.
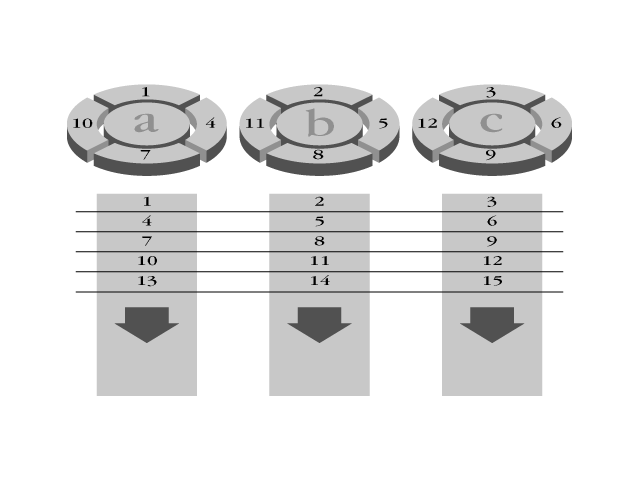
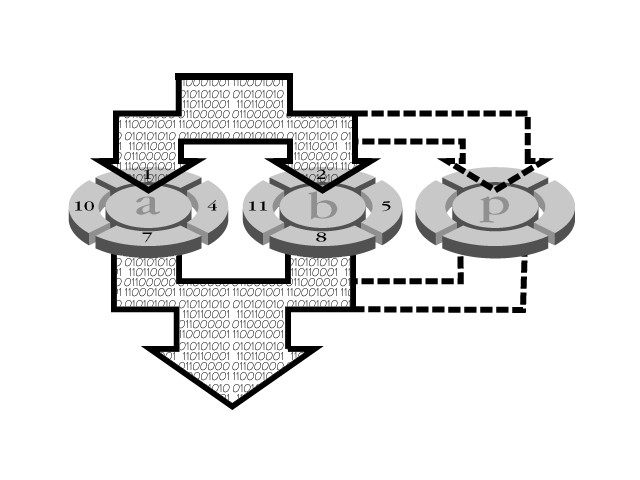
The basis for RAID is striping, which is a method of integrating several disk drives into a single logical storage unit that offers parallelism in the I/O (see Figure 12.1).
Figure 12.1. Striping disk drives. Data stripes from disks A, B, and C are interleaved to create a single logical storage unit.
The same way normal (non-stripe) storage space is organized into sectors on a single disk, the RAID system is able to partition drives into stripes. These stripes start on one disk and continue to the next. Unlike adjacent disk sectors, adjacent stripe sectors are located on different disks. This allows the individual drives to fetch portions of the data at the same time.
Stripes can be as small as one sector (512 bytes) or as large as several megabytes; the size of the stripe determines how responsive the array is. Large stripes allow for concurrent access to different files because the data is not necessarily spread across all disks. Small stripes provide quick data transfers without the concurrency because the data has to be retrieved from all drives. The stripes are interleaved in a round-robin fashion so that the storage space is composed of stripes in each drive. For each read or write transaction, each drive reads or writes its own stripe; when the stripes are combined, you have the complete data.
Unlike storage that is on separate disks, which is never balanced (data stored in one disk may be used more frequently than data on another disk), data striping divides work evenly among all drives. Balancing the disk I/O across all the drives greatly reduces the time required to access files.
Single-user systems benefit from small stripes (512 bytes) because they help ensure that most of the data spans across all drives in the array. Small stripes also help to access large files because most of the operations can occur concurrently. The negative effect of a small-stripe partition is that if the drives are not synchronized, performance worsens relative to the number of drives in the array. This is because the I/O operation is not completed until the last disk drive has finished its read or write operation.
There are several different RAID topologies, labeled RAID 0 through 7.
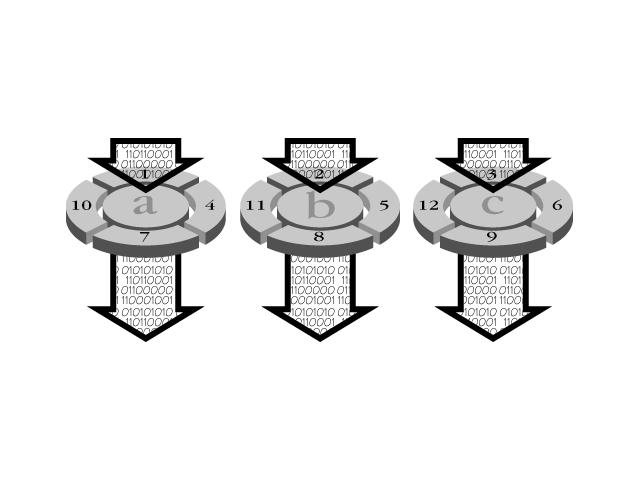
RAID 0 is a non-redundant group of striped disk drives. That means that if one drive fails, the entire array fails. Failure is an important concern of any RAID strategy. Under a RAID setup, the Mean Time Between Failures (MTBF) rating listed by a drive should be divided by the number of drives in the setup. A diagram of RAID 0 can be found in Figure 12.2.
Figure 12.2. Non-redundant striped array. Data stripes from disks A, B, and C are interleaved to create a single logical storage unit. Reads and writes can occur concurrently on all drives.
The best performance in any RAID configuration is on a RAID 0 configuration. This is because no data-integrity processing is done on read or write operations, and because disks can perform concurrently. The array can have two or more disks.
RAID 0 supports multiple concurrent read and write transactions on short requests. Longer read and write transactions can be split and handled concurrently.
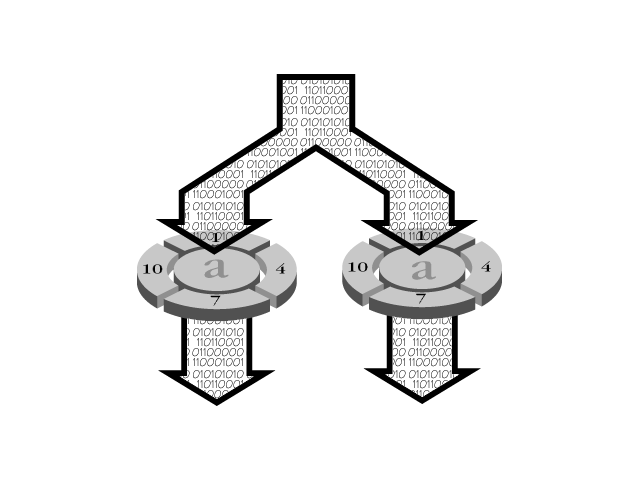
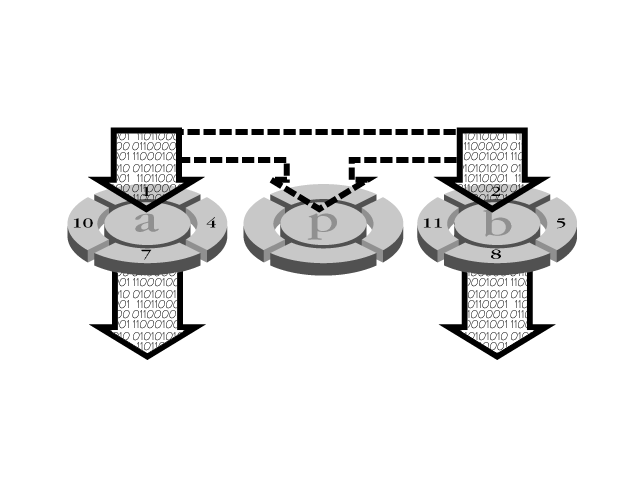
RAID 1 provides disk mirroring—information is duplicated to both disks. Each adapter manages two drives. There is no striping between the two disks; information is duplicated to both disks. However, you can stripe several RAID 1 arrays together. A diagram of RAID 1 can be found in Figure 12.3.
Figure 12.3. A mirrored array. Data is written in duplicate to drives A and B. Different read transactions can occur concurrently on either drive.
To maintain the mirroring, both disks write the same data. Therefore, RAID 1 offers no performance gains on write accesses. However, different read transactions can occur simultaneously, with a performance increase of 100 percent. RAID 1 delivers the best performance of any RAID in a multi-user environment. It provides faster short- and long-read transactions because the operations can resolve to either of the disks.
Write transactions are slower because both disks must write the same amount of data. Implementing RAID 1 can be quite expensive because it requires double the number of disks and double the storage capacity.
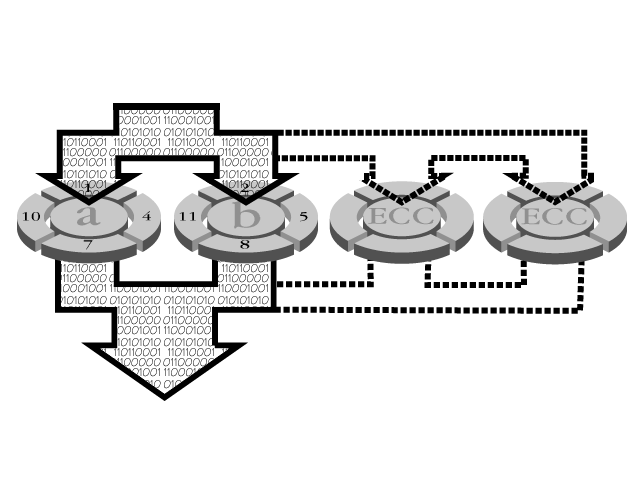
RAID 2 uses a sector-stripe array. Data is written to a group of drives with some drives storing the ECC. Because most modern drives store ECC information at the end of a sector, this configuration offers no particular advantage over a RAID 3 configuration. A diagram of RAID 1 can be found in Figure 12.4.
Figure 12.4. Parallel array with ECC. Multiple drives are striped for data storage. ECC is stored on one or more drives. Read and write transactions span all drives.
The ECC is calculated from the multiple-disks stripe and stored in a separate drive. Reads happen at normal speed. Writes are slower than normal because of the ECC that needs to be calculated and stored.
RAID 3, like RAID 2, sectors data into stripes across a group of drives. Error detection is dependent on the ECC stored in each sector on each drive. If a failure is detected, data consistency is assured by mathematically calculating the correct data from information stored on the remaining drives. Files usually span all drives in the array, making disk transfer rates optimal. However, I/O cannot overlap because each transaction affects all drives in the array. This configuration provides the best performance for a single-user workstation. To avoid performance degradation on short-file accesses, synchronized drives, or spindles, are required. A diagram of RAID 3 can be found in Figure 12.5.
Figure 12.5. Parallel array with parity. Multiple drives are striped for data storage. Parity is stored on one drive. Read and write transactions span all drives. In the event of a hardware failure, the data from the failed drive can be reconstructed on-the-fly from the data stored on the other drives.
The configuration of RAID 4 is the same as that of RAID 3, but the size of the stripes is larger, which allows read operations to be overlapped. Write operations have to update the parity drive and cannot be overlapped. This configuration offers no significant advantage over a RAID 5 configuration. RAID 4 disk arrays can have three or five disks. A diagram for RAID 4 can be found in Figure 12.6.
Figure 12.6. Striped array with parity. Stripes in this configuration are larger, so read and write transactions can occur concurrently. Because there is only a single-parity drive, all write transactions need to update the parity drive.
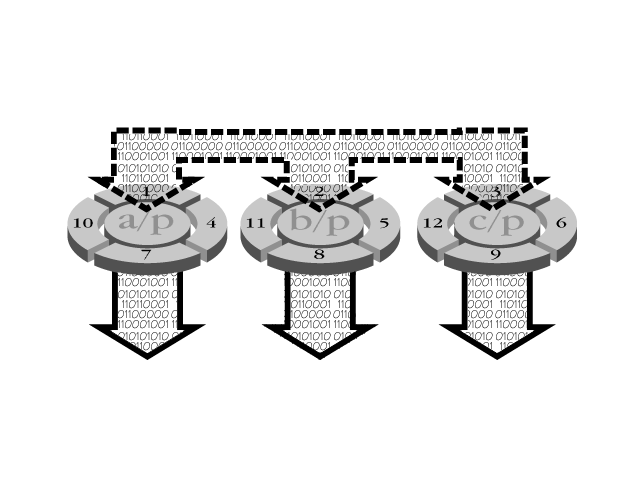
RAID 5 implements a rotating parity array that eliminates the bottleneck of the single-parity drive configuration used in RAID 4. RAID 5 uses large stripes to enable the overlap of multiple I/O transactions. Each drive takes a turn storing parity for a stripe. Most write operations access only a single data drive and the current parity drive. Write operations can overlap. A diagram for RAID 5 can be found in Figure 12.7.
Figure 12.7. Rotating parity array. All drives store data and parity information. Reads and writes can occur concurrently.
This is the best configuration for a fault-tolerant setup in a multi-user environment that is not performance sensitive or that performs few write operations. Disk arrays can have between three and seven disks. RAID 5 is efficient because it uses parity information instead of duplicating data. However, because parity information must be calculated for all drives with each write operation, write operations are not as efficient. This setup is not recommended for applications that write data. Read operations, such as those sustained by a Web server, are better with RAID 5 than with the RAID 1 counterpart. For a Web server application, RAID 5 provides the best performance and reliability.
RAID 6 describes a scheme involving a two-dimensional disk array that promises to tolerate any two-drive failure; however, no commercial implementation of RAID 6 exists as of this writing.
RAID 7 is a marketing term created by Storage Computer, Inc. Information on the Internet about RAID 7 indicates that while some of RAID 7's performance claims may be worthwhile, RAID 7 is controversial because of its use of a cache. A few major vendors have started to introduce RAID 7 products. RAID 7 is basically just RAID with caching.
Some operating systems include software striping options, which allow your system to effectively implement RAID. However, there is a tradeoff in performance, as well as additional CPU overhead, when these options are used. Some of the vendors and operating systems that offer software striping options include Silicon Graphics, Linux, and Hewlett-Packard and Sun. For more information, check your UNIX documentation.
For a busy site, network tuning will be the second major performance issue you'll face. Even if your disk subsystem is tuned for optimal performance, its impact will be limited unless you are able to push data through the wire quickly enough. Here are a few issues to consider:
These issues can be addressed by limiting traffic to well-defined sections of your network or by adjusting the size of your network plumbing to match your needs. The bigger the pipes and the pumps, the better the performance.
How much bandwidth you have depends on the type of service to which you subscribe. For Internet information providers, this is generally some sort of leased line. The faster the line, the more expensive it is. Top-of-the-line DS-3 services cost tens of thousands of dollars per month. This figure doesn't even include the initial cost of the networking hardware, which can easily be over $80,000, plus any other setup fees and the rental of the line! New technologies are going to increase bandwidth for consumers, and if the pricing is attractive, many providers may begin looking at them as possible additions to or replacements of their current leased lines. (See Table 12.1.)
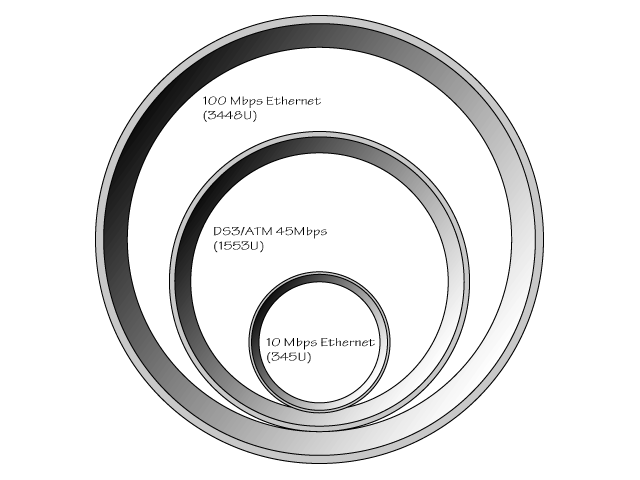
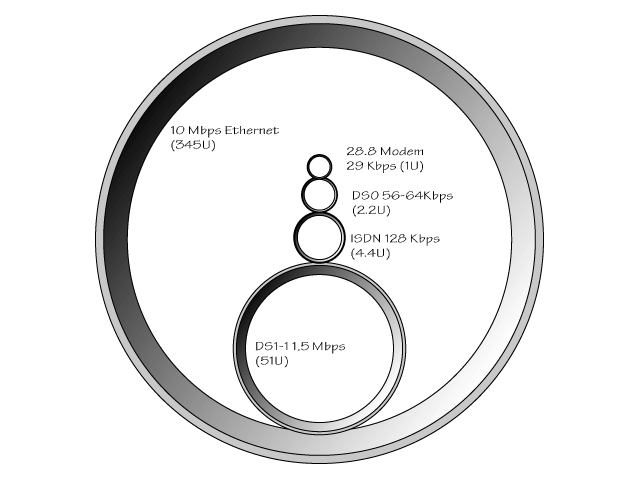
Telephone companies, with their huge infrastructure, are in a position to bring the price of this technology down, making it affordable to almost anyone. Network plumbing varies greatly in price and performance. For a graphical comparison of the various options, see Figures 12.8 and 12.9. The shaded areas are proportional to the amount of data they can carry. Table 12.1 presents the various services available for a WAN interface and the monthly costs associated with them.
Figure 12.8. Relative size comparison of 100Mbps Ethernet, DS-3, and 10Mbps Ethernet.
Figure 12.9. Relative size comparison of 10Mbps Ethernet, DS-1, ISDN, DS-0, and 28.8 modems.
| Service Type | Bandwidth | Price/Month |
| DS-3/ATM | 45,000Kbps | >$25,000 |
| ADSL/DMT Modems* (downloading) | 1,500-8,000Kbps | Unknown |
| T-1 or DS-1 (Digital Service 1) | 1,500Kbps | $770–$950 |
| ISDN | 128Kbps | $325–$450 |
| ADSL/DMT Modems* (uploading) | 64-768Kbps | Unknown |
| DS-0 (Digital Service 0) | 56-64Kbps | $180–$225 |
| Modem | 29Kbps | $95–$150 |
The Price/Month column doesn't include costs related to leasing the line that connects you to the Internet Service Provider (ISP). Typically, you could approximate costs by figuring that a single voice line is $30/month. 28.8 modems, DS-0, and ADSL/DMT lines* take a single line. Any other service requires multiple lines. An ISDN line requires two lines ($60/month); a DS-1 line requires 24 lines ($720/month); a full DS-3 needs around 672 lines ($20,160/month).
Dedicated network connections vary in price depending on your geographic location, your distance from the provider, the length of your contract, and other factors. The following sections describe the most common services.
DS-0 service is used to enhance two-wire or four-wire voice or analog data, providing a single transmission channel between the end user and the provider. It can also be used as a dedicated link between two remote office locations.
A DS-1 service has a capacity of 1.544Mbps and can carry up to 24 64Kbps voice-grade signals. This service is also known as a T-1, referring to the "T Carrier" digital communication system.
A DS-3 circuit has the capacity of 44.736Mbps. It is the equivalent of 28 DS-1 circuits, having a capacity of 672 voice-grade signals. This service is also known as a T-3. This is a very high-capacity service.
New technology, such as Discrete Multitone ADSL, promises to deliver incredible performance inexpensively. The technology, intended for consumer Internet access, has varying rates of bandwidth depending on the direction of the transfer. Downloads that operate from DS-1 to almost Ethernet speeds are sure to be hot with consumers. Uploads range from 64Kbps to half of a DS-1 line—respectable performance, considering that it operates over existing copper lines.
ISDN is a service that allows the combination of voice and data connections over a single high-speed connection. The quality of the voice line is better than the standard voice line because the service is digital. This service works over existing copper wires and requires a modem-like device. The typical consumer ISDN modem costs around $300.
The type of LAN you implement on your network will greatly affect the performance and reliability of your server.
An Ethernet network is a well-behaved, polite group of computers. If one talks, the others listen. However, that means that the more systems there are on the wire, the more time computers are going to spend waiting to talk. If two talk at the same time, a packet collision occurs. On detecting a collision, all computers will randomly reset their talk interval to avoid a deadlock, which is a condition where the collision continues to occur due to a predetermined silence period.
One way to improve performance is to have a faster Ethernet. The faster the network, the quicker the packets travel and the more opportunity each system has to talk and deliver its message. Ethernet LANs come in two flavors: 10Mbps and 100Mbps.
In contrast to most WAN interfaces, Ethernet networks are very fast. However, Ethernet network capacity is only 60 to 80 percent of the rated bandwidth. On a 10Mbps Ethernet network, a server responding to 100 requests per second, each request having an average size of 7KB, is using roughly 60 percent of the available bandwidth. A network experiencing this sort of activity should have a 100Mbps Ethernet backbone support.
Software tuning will allow your system to operate optimally given a load. There are several configuration details that will make your system more efficient; they are detailed in the following sections.
The HTTP server software is critical. The Apache server in its default configuration is already tuned very well. Apache provides you with configuration directives that allow you address just about every issue that could affect the performance of your server. These directives cover issues relating to the life of the HTTP children processes, the maximum and minimum number of processes the server runs, whether to enable server-side includes or per-directory access control files, and so on. Configurability is one of the big strengths of the Apache server. If the server does it, you can configure it.
You will achieve maximum performance for your HTTP server by following these tips:
Your operating system's TCP/IP implementation determines the number of connections, the connection rate, and the maximum throughput that your system will achieve. Some of the default settings for your kernel may not be adequate for a high-traffic Web server.
Before you attempt to fix anything, you should try to determine whether your system has a problem. The netstat program provides a wealth of information that you can use to determine what is going on.
The following sections explain of the enhancements you'll need to do yourself, presented system by system.
A frequent source to TCP/IP performance problems is attributed to the system call listen(). The listen() call is responsible for enabling incoming connections for a socket. The source of the problem is that the call sets a backlog parameter that specifies the maximum size that the queue of pending connections may reach. If the number of waiting connections grows beyond the defined size, the client will receive an error message that will prompt the client to issue a new request. Typically, the backlog parameter is set to 5, which is hopelessly inadequate.
To determine whether your system is running into trouble because of the listen backlog, type the following command:
netstat -n | grep SYN_RCVD
If you continually don't get any lines listed, the listen backlog issue is not causing you grief. However, if you regularly get six or seven lines, you may be running into trouble.
The only ways to fix this problem are to rebuild the kernel or to apply a runtime kernel patch that increases the value of the backlog variable. If your Web server is a busy one, you definitely want to address this problem. Please note that the valid ranges for each OS are different. The great majority of operating systems can only use 256 as the maximum value.
If you rebuild your kernel, make sure you have a backup of your old kernel plus any necessary files, such as /vmunix. That way, in case of trouble, you can boot your computer using the old kernel. For more information on rebuilding your kernel, look at your system documentation. If you make changes to your kernel and do not have the hardware resources to match your settings, it is very likely that your computer will boot to a kernel panic.
A/UX has a hardwired SOMAXCONN. You will need the patch BNET-somax.tar.gz, available from ftp://ftp1.jagunet.com/pub/aux/.
This patch is just a simple ksh script that patches the runtime kernel using adb. The documentation included in the patch specifies how to install it at system startup time.
Look for the SOMAXCONN definition:
#define SOMAXCONN 5
which is typically found in
/usr/include/sys/socket.h /usr/src/sys/sys/socket.h
Change the value from 5 to 32. After you make your changes, you will have to rebuild your kernel and reboot your system.
You need to patch the kernel's global variable somaxconn using dbx -x. The default value is set to 8, but you can bump it up all the way to 32767. Servers with high traffic shouldn't even consider values that are less than 2048. Digital's Alta Vista servers get 5 million hits per day, and they probably have set theirs to 32767.
Digital has also published some patches that address the listen backlog and other related performance issues regarding Web servers. The patch ID is 0SF350-146. This patch improves the performance of the network subsystem for machines used as Web servers.
Modify the following lines in /usr/src/linux/net/inet/af_inet.c:
... if ((unsigned) backlog > 5) backlog = 5; ...
Replace both instances of 5 with the size of the listen queue you want. A valid number ranges from 0 to 255, but some experts suggest not exceeding 128. Then rebuild your kernel.
On Solaris 2.4 and 2.5, you can patch the running kernel using the ndd command. To patch SOMAXCONN, type
/usr/sbin/ndd -set /dev/tcp tcp_conn_req_max N
where N is a number. On Solaris 2.4, the maximum value of N is 32. Solaris 2.5 defaults to 32, and the limit is 1024. You will probably want to patch this value automatically at system startup time. Do so in /etc/rc2.d/s69inet, putting the preceding command at the end of the file. For more information on ndd, check the man page.
Under SunOS 4.1.3, things are not as easy. Unless you have licensed the kernel code, you will have to patch the object code file that defines those values. The object code file is
/sys/sun4m/OBJ/uipc_socket.o
Of course, you should make a backup of the uipc_socket.o file before you proceed.
These modifications involve changing a value stored at octal locations 0727, 0737, and 0753 in the preceding file. You can change these values using the following program:
/*This program was originally developed by Mark Morley (mark@islandnet.com), and was copied with permission*/
#include <stdio.h>
main()
{
FILE* fp;
fp = open("/sys/sun4m/OBJ/uipc_socket.o", "r+");
if (fp != NULL){
fseek(fp, 0727, 0 );
putc( 128, fp );
fseek( fp, 0737, 0 );
putc( 128, fp );
fseek (fp, 0757, 0 );
putc( 128, fp );
fclose( fp )
printf("/sys/sun4m/OBJ/uipc_socket.o was successfully patched.
[ic:cc]You need to rebuild your kernel and restart\n");
exit(0);
}
printf("Sorry /sys/sun4m/OBJ/uipc_socket.o could not be open\n");
exit(-1);
}
Most HTTP requests will involve a disk access, so the performance of your file system will be tested. Some systems allow you to implement RAID in software at the cost of some additional processing overhead.
If a significant number of the requests processed by your server involve CGI execution, the performance of your Web server will be closely related to the performance of the CGI programs.
CGI is inherently inefficient; request requires the server to fork a process. The process then needs to initialize itself, execute, and exit. If the CGI is based on some interpreted programming language, such as Perl or Tcl, the process is even more demanding because an interpreter will have to be launched, the script compiled, and then finally executed.
Porting your CGI to a compiled language is one way of improving the performance of your programs. Another way of enhancing program performance is by using FastCGI or an imbedded interpreter, or in some cases, by developing a server module that accomplishes what you need.
If you have a server that frequently incurs hits from CGI programs, you might want to consider one of these solutions:
Porting the most-used CGI to C or some other compiled language will increase performance a lot. You may want to take a look at server-side compiled JavaScript or WebObjects as an environment to develop Web applications (intranets).
WebObjects offers some very interesting technology. WebObjects was developed by NeXT Software, Inc. (http://www.next.com), a leader in object-oriented software development technology. The WebObjects package currently runs under Windows NT, Sun Solaris, NEXTSTEP, and OPENSTEP for Mach. A version will be available for Hewlett-Packard's HPUX in the near future.
WebObjects is an environment for interfacing objects to the Internet via the Web. WebObject's object technology is based on NeXT's OPENSTEP technology. It uses NeXT's Enterprise Objects Framework (EOF) for database access and Portable Distributed Objects (PDO) for object distribution. PDO provides automatic load balancing of CGI between various CGI servers. It all happens automatically, and is fully compatible with any HTTP server with a CGI, ISAPI, or NSAPI interface (including Apache). WebObjects allows you to publish dynamic content and materials obtained from a database or some other dynamic source through the Web.
WebObjects provides the scripting language WebScript. It will also provide full support for VBScript, Perl, and JavaScript in the very near future.
Of the various options, FastCGI may be the one you'll want to explore first because it can potentially provide you with the greatest benefits while requiring the least efforts. For more information, check out Appendix C, "FastCGI."
FastCGI is a high-performance extension to the CGI standard that offers a significant improvement in performance over the existing CGI program interface. FastCGI is improved CGI; however, the programming methods are virtually the same. FastCGI accomplishes its performance enhancement by having the CGI be a long-lived process. The long-lived process remains ready to serve requests until it is destroyed by the system administrator or the server stops running.
This difference can have a dramatic effect on the performance of your programs and the servers that run them. The performance savings are really noticeable especially if your program needs to establish a connection with a database or some other process. A FastCGI application will maintain a connection to the database server, eliminating this time-consuming step. FastCGI requests are almost as fast as requesting a static document, and that is a tremendous improvement!
Another way of reducing the CGI load is to dedicate servers for CGI execution. Netscape runs CGI servers on their network.
FastCGI can be used for this purpose as well. It can connect to any process via a TCP/IP connection. This means that you have your Web server separate from your FastCGI servers.
Some CGI development systems offer automatic CGI load balancing. WebObjects allows you to use distributed objects that provide services to any processes on your network. The system is distributed by design. When a process looks for a service, it will bind to the first server process that answers the request. This has the effect of making the least utilized servers the ones more likely to answer first, hence the load distribution. Not only can one item be distributed, but different objects can seamlessly bind to other objects in the network, making the application truly distributed.
More and more applications of Web server technology involve intranet technology. An intranet is an internal application deployed over the Web. Web technology is proving to be a viable solution for implementing client-independent mission-critical applications. Any system capable of using a browser has access to the corporate information. This scales well when you consider that a typical network houses systems of various architectures and operating systems. Software development on the server side ensures a great reduction in software-development costs. Intranet applications ultimately depend on the performance of the database server and the CGI programs used to access the data.
Although there are a few well-known ways to increase your Web server's performance, such as the SOMAXCOMM kernel variable discussed in the preceding section, there are other software bottlenecks that are less known.
As operating-system vendors are learning about these bottlenecks, they are quickly fixing them. Some of these kernel enhancements offer Web server speed improvements of 33 percent or better over previous versions of the operating system. One of the best things you can do as a webmaster is keep informed of these updates and evaluate whether these changes will enhance your system.
You might want to update the NMBUFS kernel variable if you are finding many connections with a TIME_WAIT status. You can easily determine how many connections have this status by running the netstat command. The value you need for NMBUFS should be a lot higher than you might think. Mid-transfer disconnections will make sockets unavailable for several minutes, impeding the formation of new good connections. A good value for NMBUFS is 4096.
You may want to up the maxusers kernel variable. This variable controls several things, including
If your server is heavily loaded, you might want to consider upping maxusers to 256, but make sure that you have enough RAM resources for that. The maxusers variable will increase the value of several other kernel variables. For information on the values derived from the maxusers variable, see the file /usr/src/sys/conf/param.c.
If you find that there are many connections with a TIME_WAIT status when you run the netstat command, you may want to up the NMBCLUSTERS value. The value you need for this should be a lot higher than what you might think. Mid-transfer disconnections will make sockets unavailable for several minutes, impeding the formation of new good connections. A good value for NMBCLUSTERS is 4096.
In the file /usr/src/kernel/linux/include/fs.h changes NR_OPEN from 256 to 1024 and NR_FILE from 1024 to 2048.
The number of hosts that you have on your network will affect your network's overall performance. By rethinking and reorganizing the layout of your network, you might be able to reduce your network traffic, allowing the server to send and receive data.
Before discussing how the size of the pipe affects your data speed, it is useful to understand just what travels through your pipe. After all, you cannot be a plumber until you know about water. The water in your network is the data, and its motion through the wire on the Internet is controlled by a set of networking protocols known collectively as TCP/IP. TCP/IP is named after the two main protocols used: Transmission Control Protocol (RFC793) and Internet Protocol (RFC791).
The success of TCP/IP is attributed to its design. It was developed under an open standard, which means the protocol is independent of any particular operating system or hardware. Because of this independence, TCP/IP is able to run over a dial-up connection, Ethernet, X.25 Net, token rings, or virtually any other physical medium.
The TCP fits into a layered protocol architecture above the Internet Protocol. The Internet Protocol provides TCP with a mechanism to send and receive data packets of variable length that have been prepackaged in an Internet envelope, also called a datagram.
The datagram provides a way of addressing the sender and recipient TCP packets in different networks.
The layers used by the protocol are
The Network Layer is responsible for handling the specifics of moving a piece of data through the underlying hardware. This layer also manages electrical voltages and interfaces (connectors), as well as packet sizes and structures required to transfer a packet from one point to another through a particular network. This portion of the protocol is not part of TCP; rather, it is merely used by the protocol. Hardware designers are responsible for implementing the details necessary for the TCPs to be able to use the underlying hardware.
The Internet Protocol Layer, or Routing Layer, is the foundation of the Internet. It defines the transmission unit, the datagram, and the addressing scheme; connects the Network Layer to the TCP Layer, routes datagrams between hosts, and splits and reassembles datagrams into sizes appropriate for the underlying network hardware.
A datagram, as I mentioned, is the envelope used for delivering the data. It contains several pieces of information, including the source address that generated the datagram, the destination of the datagram, a serial number so that the data can be reassembled in the right order, and a check sum value that can be used to determine whether the datagram arrived intact.
When a datagram is sent between two hosts, if the recipient host is outside of the local Net, it gets forwarded to a gateway. This gateway is typically a router. In turn forwards the datagram to other gateways until the datagram is delivered to a gateway that knows how to deliver it to its final destination—a host or another device local of that network.
A router is a specialized computer that forwards datagrams across networks. Although this might seem like a simple task, it is in fact quite involved. Packets not acknowledged within the given time period will get re-sent, requiring the router to figure out where to process and forward packets rapidly. Routers build dynamic tables to help forward datagrams to different networks. If a router has various ways of forwarding the datagram, it will (unless directed by a static route) forward the packet in the most efficient way possible.
In order for one device to communicate with another on an IP network (be it the Internet or your local TCP/IP network), each device must know three different pieces of information:
An IP is an address format used on TCP networks and the Internet. It is composed of four or more 8-bit numbers represented as octets. A new standard allows addressing 2^128 computers, roughly—my calculator doesn't go that far!—3.40282367E38, which is a huge number! It has been said that under this scheme there are enough addresses to put 10 computers per square meter all over the world. For simplicity's sake, I'll stick to the old 32-bit implementation for these examples. Each octet can represent values ranging from 0 to 255, allowing 256 unique values. Each octet is separated by a period. Here's a sample IP address: 1.2.3.4
The maximum number of hosts that you can address on an IP network is set by the class of the address. There are currently three address classes: A, B, and C. (See Table 12.2.)
| Address Class | Network Portion | Hosts Allowed Per Network |
| A | 1.-127. | More than 16 million |
| B | 128.0-191.255. | 65,536 |
| C | 192.0.0-223.255.255 | 255 |
In order for a device to work on a network, it needs to know three addresses:
The IP address is the address of the device. Outside networks don't know anything about your subnet mask, which is just an internal organization tool for you. Instead, outside networks reference the device by its IP address. The network mask tells your router how to interpret the IP address, specifying which portion of the address corresponds to the network address and which portion corresponds to the host portion of the address.
The broadcast address is a special address to which all devices on the network listen. Routing information is propagated this way, as are messages you send using the UNIX wall (write-all) program. Typically, address 0, or the first address in the subnet range, belongs to the address of the network or subnet. Address 255, or the last address available to the subnet range, is used as the broadcast address. (See Table 12.3.) What this means to you is that when you add a subnet, you give away two IPs per subnet for overhead in exchange for the organizational and performance benefits of subnetting.
The number of hosts available listed in Table 12.3 takes into account the requirement for a network and broadcast address.
Typically, unless you are a large organization, your IP address will be a C-class address. Even if your gateway to the Internet is through a DS-1 line, having a 100Mbps Ethernet network may improve the performance and responsiveness of your servers, as well as help you maximize the potential of your DS-1 line.
Another way is to improve performance is to reduce the amount of traffic that gets into your network in the first place. If you have a busy Web server, network traffic to and from the server will slow your local network activity. By segmenting your network into various smaller networks, you allow each of the segments to operate at peak performance. If you have high traffic, you might want to consider putting your Web server on its own subnet.
Subnetworks require the installation of additional hardware, namely bridges or routers. Routers don't grab packets that are not destined for their LAN. By subnetting, you are basically reducing the number of hosts you can have on each subnet, thus eliminating the amount of data that can travel through your subnet. Only traffic that is destined for elsewhere will exit the subnet. If you organize subnets around workgroups, you will have the opportunity to better your network organization. Some of the benefits of subnetting follow:
Building a subnet is not too tricky. However, there are a couple of things that you will need to understand: the math behind network masks and the reserved IPs that you cannot use for a machine.
The main thing you must decide is the number of segments you want to create. Subnetting works by specifying a different network mask from the default. The network mask specifies how many bits of the IP address belong to the network portion of the address. However many bits are left can be used for the host portion of the address. Table 12.4 lists the default network mask for each address class.
| Address Class | Default Mask |
| A | 255.0.0.0 |
| B | 128.0-191.255 |
| C | 192.0.0-223.255.255 |
Some of the octets represent network numbers others represent host numbers. Each octet represents a function of the network mask. A mask is simply a binary number that specifies which bits belong to the network and which bits belong to the host portion. Bits that are "on" (represented by 1) will be used for network address.
For example, if you have an IP, such as 204.95.222.100, and the mask for this IP is 255.255.255.0, you can determine that the host portion can use all bits in the last octet; that amounts to 256 unique values ranging from 0-255. I find it easier to work with masks in binary:
204.95.222.100: 11001100.01011111.11011110.01100100 255.255.255.0: 11111111.11111111.11111111.00000000
In the next example the mask was set to 255.255.255.128:
204.95.222.100: 11001100.01011111.11011110.01100100
255.255.255.128: 11111111.11111111.11111111.10000000
This mask yields an extra bit for the network address (shown in bold). This means that you can have two subnets, and the host portion can use 7 bits, or 127 unique addresses, for each of the subnets.
Caching proxy servers can be a powerful tool in your arsenal to increase the performance of your internal Web traffic. While originally developed as a way of allowing access to the Web through a firewall, proxy servers can also be used to reduce the traffic your organization generates to popular Web sites.
Versions of Apache, beginning with 1.1, include a caching proxy server module that enables Apache to function as a caching proxy server.
A proxy server is a Web server that sits between a local client and an external Web server. It acts as an intermediary to the client and fetches information from other Web servers. Instead of a client connecting to a server on the Internet directly, it establishes a connection with a proxy server in the user's local network. The proxy server then retrieves the resources requested and serves them to the client as if the resources were its own.
Besides negotiating a transaction for a client, proxy servers usually cache data they receive from other servers. Over time this cache will grow rich in pages from the most popular destinations on the Internet, allowing subsequent requests to be served from the local proxy.
Instead of each request consuming your WAN bandwidth, subsequent requests to the same URL are served from the cache, locally and at LAN speeds. This virtually eliminates the bulk of the traffic to previously contacted sites and improves access times dramatically. This functionality has the effect of freeing bandwidth that would have been used to download duplicate information for other purposes, such as to serve your company's pages to outside users.
If your connection to the Internet is not very fast, a catching proxy server can help you enhance your access to some of the most frequented sites on the Internet. Obviously, performance enhancements you obtain from a cache will depend on the richness of the cache, the surfing patterns of your users, and the amount of disk resources that you are willing to dedicate for this purpose.
Overall, dedicating a caching server in your organization may provide many potential benefits to warrant its deployment. Setup of a proxy is not complicated and requires very little administrative time.
So far, most of the issues I have talked about revolve around the software and hardware behind the server, but it is worth mentioning that there is one more way you can optimize performance.
The less bandwidth that your content requires for transmission, the more quickly transfers will occur. Organizing and breaking your documents into smaller pieces will help tremendously. For example, if you have a DS-1 line, you are capable of transmitting about 200KB per second. If your line were to support 50 users per second at optimal speed, your average reply should not exceed 4KB. Although requiring that each of your pages be 4KB in size is a very unreasonable request, it can help you to understand how many users your line can realistically support. The smaller your line, the smaller your reply content should be.
I have seen many Web pages that take quite a few seconds to download. Pages and images that are carefully designed can help provide the feel of a very fast site. Many designers who develop graphics for Web pages don't know how to prepare graphics that maximize the intent of the work while minimizing image size.
If you are using Graphical Interchange Format (GIF) files, you should be aware of Netscape's color cube. Netscape's color cube only supports 6x6x6 combinations of colors, or 216 colors. Any color that doesn't fall in the cube will be dithered. The Netscape color palette includes the values 00, 33, 66, 99, CC, and FF for each of the RGB channels. Some programs, such as Adobe's Photoshop, allow you to specify a custom color lookup table (CLUT) when converting images to GIF format. If you map and dither to this CLUT, what you see on your screen is what everyone else will see too.
Also, be aware that Netscape has only four grays plus black and white, which can be very limiting. If you have artwork that is grayscale (no color), convert it to grayscale and then back to RGB format. This will set any pixels that dithered to a grayish tone but still will contain some color information to a true grayscale. You can then convert your artwork to GIF and map the grays to those that fall within the cube.
For a very interesting resource, visit http://www.adobe.com. This site has information on color reduction techniques that are very effective. They also have a CLUT available that you can use in Photoshop, which contains the Netscape palette.
Also visit the home of the Bandwidth Conservation Society at http://www.infohiway.com/faster/index.html. Their site contains a lot of information on how to get the most out of your images without requiring huge file transfers.
Another great tool that I use all the time is DeBabelizer. DeBabelizer is a powerful graphics program by Equilibrium ( http://www.equilibrium.com) that can translate between many image formats. More importantly, it has a great color dithering algorithm that will reduce colors (reduce the file size) while maintaining an equally pleasing image. In most instances the results are amazing, and the reductions are significant. Color reductions by this software render equally well on all graphically capable browsers, eliminating color discrepancy issues.
Photographic images are usually smaller, and they dither better when saved in Joint Picture Experts Group (JPEG) format. Be aware that some old browsers don't support in-line JPEG files.
Client-side image maps embed the map file right into the HTML document sent to the client. On selection, the browser does the hit detection and requests the appropriate document, instead of passing down the coordinates where the user clicked back to the server.
Client-side image maps will help remove a load from the server. However, their operation is not reliable on all browsers yet, and it's only supported by Netscape and Microsoft Internet Explorer. Netscape seems to dislike polygonal areas, while Microsoft Internet Explorer seems to work just fine.
This chapter covers a great deal of topics. Tuning your system for efficiency as you can see covers every possible area. There's so much an Administrator can do that it is impossible to cover it all in one chapter. Your best strategy is to determine where the bottlenecks are and what can be done to address them. Many of the solutions will involve money. To make your action list work, you may want to assign a price to all possible solutions. That usually helps you to narrow your choices.
A great resource for tuning your server is Adrian Cockroft's Q&A article. It is available at http://www.sun.com:80/sunworldonline/swol-03-1996/swol-03-perf.html.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}