| Table of Contents Previous | Next |
Apache Server Survival Guide |
HTTP servers provide information; however, if your servers are unreachable, no one can get at this information. Your job as a system administrator is to ensure that your computers and networks are running smoothly. You must be both proactive and reactive. A proactive system administrator monitors his system resources to prevent basic problems, such as running out of disk space or some other disaster. A reactive system administrator has a contingency plan ready to be implemented in case of a disaster.
Proactive system administration is better than reactive system administration. Proactive administration can help you avoid the unpleasant experience of responding to a barrage of users' complaints about services that are down. However, should such a situation arise, your efficiency in resolving the matter (reactive administration) will affect how those complaining users perceive you and your level of competence. Therefore, it is your responsibility to maintain a close watch on all that is under your control.
The system administrator's central task is to orchestrate and choreograph the installation, setup, and maintenance of all hardware and software. Ancillary obligations can include setting up additional systems that help users obtain more information regarding access patterns and logs (HTTP logs and other UNIX logs).
The key word here is maintenance. This word can mean several different things: backing up your computers, pruning logfiles, and ensuring that name servers and HTTP servers are running. The most important of these is backing up your computers. If your system catastrophically failed, how long would it take you to get it up and running again? If it took you weeks to set up and install everything the first time, doing it over is not acceptable and definitely not fun. Instead, do it once and back it up. In case of a failure, replace the hardware or software that caused the failure with your backups.
If your information system is critical to your organization, any downtime is unacceptable. This means that you must build redundant systems that guarantee the trouble-free, continuous operation of your site. How much you can do depends on your budget.
Backing up is not hard to do, and if you want to keep your job as a system administrator, you should consider it an essential task. Although backing up is not difficult, it is tedious and time-consuming, especially when the disks you are backing up are large.
How can you back up a heavily used resource without taking it down and making it unavailable? How often should these backups occur? The answer to both of these questions is that it depends. A server that constantly has new information on it needs to be backed up more often than one that rarely changes. If your server is also a fileserver on which users or other programs store data, all bets are off. You don't have the luxury of determining what is a good interval; you will have to back it up daily.
Some technologies, such as Redundant Arrays of Inexpensive Disks (RAID), can provide automatic reliability, in case of media failure, and uninterrupted operation during hardware replacement. If a single drive on a RAID configuration fails, the data can be reconstructed from the information stored in the other drives and the redundant parity or Error Correcting Code (ECC) information. However, this feature will not help much if the root of the problem is a bad disk controller or some other problem that compromises the integrity of your data. RAID reliability is dependent on only a single drive going bad. RAID-6 arrays address this problem by allowing up to two disk failures without compromising the data. However, these multidimensional disk arrays have never been commercially implemented. Because of the auto-correcting nature of RAID, problems with the disk array are often found only when a second drive goes bad. By that time it's usually too late, and the likelihood of irreparable data loss is great. I suggest that you monitor your RAID array on a daily basis and back it up to ensure that you have a way to restore your files.
The good news is that Web servers don't change too often. If your machine is dedicated to just serving pages, your site will change when someone modifies it by adding, deleting, or updating information on the pages. The site also will change when you configure your server or install some new piece of software. How often you do backups depends on how much you are willing to lose. Keep in mind that your server logs may contain valuable information that takes time to accumulate, and unless you back them up, they will be lost. If your server also handles any sort of commercial transactions, you may want to make sure that the point-of-sale information is safely backed up.
How you handle your backup strategy is really a matter of personal preference. If you establish policies, such as describing what you back up, it becomes easier to do many system-administration tasks. Also, it is important to have the right hardware for making backups. By right hardware I mean that the disks you back up must fit into a convenient backup medium; otherwise, you'll have more tapes than you'll know what to do with. If you can afford it, buy a tape drive. This medium is inexpensive and can hold a lot of data. Other backup solutions may work on your network, depending on how much data you need to back up.
There is an incredible array of choices for backup media these days:
Floppy disks are the most convenient backup medium available because your system likely has a built-in floppy disk drive. The standard capacity is 1.44MB. Some 2.88MB drives made it into the market a few years back, but they never caught on. The drawback of floppy disks is that they are slow, fairly expensive (about 50[155] to 60[155] per disk), and not very useful for backing up anything that is larger than a couple disks.
These higher-capacity disks take advantage of optical tracking technology to improve head positioning, and therefore maximize the amount of data that can be packed onto the surface of a disk. Floptical drives can read standard 1.44MB and 720KB floppy disks. Density of information can be anywhere from a few megabytes to 200MB per disk.
Magneto-optical disks have a plastic or glass substrate coated with a compound that, when heated to its Curie point, allows a magnetic source to realign the polarity of the material. Once the material cools, its polarity is frozen. The material can be repolarized by a subsequent write operation.
Data is read by a lower-intensity beam, and the polarization pattern is interpreted as a byte stream. A wide variety of these devices are commercially available, ranging in format from 5 1/2 inches to 3 1/2 inches. These devices can store information ranging in size from 128MB to more than 2GB.
Read speed on these devices is as fast as that on a hard disk. Write operations usually take a little longer, but are still faster than write operations on a slow hard disk. Media reliability is very high.
A QIC tape is a low-end, PC-market backup storage solution that uses .25-inch tape. Some vendors, including IBM, are pushing the format to store up to 1600MB by using a .315-inch format; these tapes are commonly known as Travan tapes.
Standard QIC tapes can hold anywhere from 11MB to 150MB, and are usually designated as QIC-11, QIC-24, and QIC-150, depending on the amount of storage space they provide. Storage space in megabytes is indicated by the number following the QIC portion of the designation.
Sometimes tapes created on one vendor's drive are not readable by another vendor's drive. This is due to byte ordering and other special formatting issues. Within a vendor, tapes are usually backward compatible, meaning that you may be able to read lower-density tapes on a higher-density drive; however, you should verify this before you upgrade to a new drive in the same product line.
Travan tapes are similar in size to QIC tapes, but store anywhere from 120MB to 1600MB per tape depending on the type of tape drive mechanism used. Travan tapes are compatible with the QIC tape formats, making them attractive if you have legacy QIC tapes.
New technology and price drops have made the write-once CD-ROM a popular choice with multimedia enthusiasts. Write-once CD-ROMs use a technology similar to a CD burner. CDs created by write-once CD-ROMs are not as rugged as pressed CDs, but will last forever if you take care of the disk. These disks are compatible with any desktop system that has a CD-ROM, which has helped in making this a popular Write Once Read Many (WORM) format. Current capacity is about 600MB. Recording speed is slow. New formats for CD-ROMs that are currently in the works will yield 17GB storage, making it a very interesting solution to backup and archival tasks.
Zip is a popular removable disk drive. They are very inexpensive: around $200 for the drive and $10 to $15 per disk. Each disk holds about 100MB. They are available in SCSI and parallel flavors.
Jaz drives are a higher-performance, higher-capacity version of the Zip drives. Jaz drives are a bit more expensive, about $599, and require a SCSI interface. Disks cost more than $99 and pack 1GB of fast storage space. You can back up 1GB of information in about 5 minutes on PC platforms. This is a hot product.
This is an old format of tape written at 800, 1600, or 6250BPI (bits per inch) density. This format is not in great use today except by old mainframes.
A DAT, which stores 1.3GB of information on a 60-meter tape, was originally designed for the audio market. Digital data storage (DDS), the computer version of DAT, provides the smallest storage solution of all. You can store about 2GB of data per cartridge. Drives with hardware compression can store up to 8GB. DDS is the preferred tape backup system for most UNIX users.
8mm cartridges (also known as "Exabytes" for the company that first produced them) are the same size as their video counterparts. Many Administrators purchase high-quality "video grade" tapes instead of the premium data versions. Drives can store 2–5GB, and versions boasting hardware compression can pack up to 10GB into a single tape. Because fewer tapes are needed, this is a very convenient format. Next to the 4mm format, this is the best storage solution.
Doing incremental backups under UNIX means using the dump utility. This utility is powerful, but somewhat dangerous. Using it incorrectly can cause serious problems. However, dump can handle backups that span multiple tapes. If you can fit your entire backup onto a single tape, you'll be able to automate backups. Just start up the backup, and let it run.
Web sites have a slightly different usage pattern from your typical server. Because Web sites don't have users creating files all the time, the filesystem doesn't change very often (unless your server provides some sort of intranet application that uses a database for persistence, or you want to back up your logfiles).
A production server, the server people connect to in order to obtain information, is very different from a development server. Development servers contain an individual's work. They should be backed up often! Incremental backups should be used to minimize the media and time required to perform them.
If you have been following my suggestions, you will probably agree that the server documents (.html files) should reside on a separate disk. If you cannot afford another disk, a separate partition may offer the same benefits. Partition is just a fancy word for a smaller logical unit (smaller disk) of a big disk. Partitioning a large disk can offer many advantages:
On the negative side, if you fill up a partition, UNIX doesn't provide you with a way to enlarge or shrink it. What you choose is what you live with. Don't go partition-crazy either; if you have too many little partitions, you'll probably find that some of your partitions need more space. A two-partition scheme works well. It is a good idea to partition a disk so that the base operating system fits easily into one partition and allows 15 to 25 percent of the partition space for future growth. This is the system partition. The second partition is allocated to a single user area. Any customizations or added third-party software should go there. If you cannot afford a second disk for user-generated files, you can store them in the second partition as well.
Separate disks or partitions help the backup process because both can be dumped separately to tape. If you are unable to partition or have multiple filesystems, your backups will take a little longer.
If you follow this scheme, you'll only need to back up software and configuration files that you add or modify, instead of having to back up the whole system. Likewise, the user partition can be backed up separately.
My strategy is to back up production servers at well-defined times:
If your operating-system software distribution comes on a CD-ROM or some other easily installed medium, the first backup you make after installing your system software doesn't need to go to tape. If you send it to /dev/null, you'll be able to create a backup set that doesn't include your system's software distribution. This will set the beginning of time for the dump utility to operate. The backup level for this dump should be at level 0; it must include everything in the newly installed system.
If the installation of basic software is problematic, you should probably direct the backup to a tape and save it for future disaster recovery. If you need to reinstall your distribution software, simply restore it to a clean disk instead of rebuilding a kernel or something else.
Subsequent backups should be performed at level 9; this will effectively back up everything that has been modified in the machine since the first backup was made.
To restore files stored in a tape created with the dump utility, use the restore program.
The dump command uses the following syntax:
/usr/etc/dump [options [argument ...] filesystem]
The dump command tracks the scope of a backup by assigning each backup a level. Levels range from 0 to 9. Level 0 copies the entire filesystem. Subsequent dump levels copy only files that have changed since the most recent dump with a lower-level number.
If you dump a disk at level 5, it includes all files that have changed since the date of the last dump with the next lowest level (in this case, last level 4 dump, or lower if no dump level 4 was performed). When executed with the u flag, dump tracks the backup level along with the date and time the backup was performed.
The typical strategy is to begin with a level 0 dump and then make incremental backups at regular intervals. Level 0 dumps should be performed with extreme care; they should be run with the machine in single-user mode, and fsck, the filesystem consistency checker, should run before the dump to verify that the filesystem is consistent. This is important because most of the files you restore will come from dump level 0 tapes!
One disadvantage worth noting is that dump is unable to back up single directories or files. It can only be used to back up an entire filesystem. To back up individual files or directories, use the programs tar or cpio. For information on how to use these programs, refer to your UNIX documentation.
Note that tapes created under one hardware/software configuration are not usually portable to other operating systems or drives. On some environments, even tapes created with older versions of the dump program are unreadable by newer versions of the restore program.
The following command will create a level 0 dump (specified by the 0) of the specified disk, /dev/rsd0a:
dump 0u /dev/rsd0a
Replace rsd0a with the appropriate name for your raw disk device. This dump will include all the files found on the device. If you specify the u option and the backup finishes successfully, dump will remember the date, time, and level of this backup. This effectively sets a reference point that can be used to evaluate which files need to be dumped next time.
To create a partial backup that includes only files modified since the last backup of a lower level, in this case 0, use a level 9 dump:
dump 9u /dev/rsd0a
By default, dump writes its output to the default tape unit, in this case /dev/rxt0. The /dev/rxt0 is a rewinding interface to the tape drive. When the backup is finished, the tape will be automatically rewound. To finish the backup and prevent the tape from rewinding, use the nonrewinding device. On my system, this is called /dev/nrxt0. For the name of this device, please check the dump UNIX manual page. To specify a different backup device or file, use the f option:
dump 9uf /tmp/backup /dev/rsd0a
The preceding command will create a file called backup in the /tmp directory. To redirect dump's output to stdout (standard output), specify a - instead of a filename:
dump 9uf - /dev/rsd0a | gzip > /tmp/backup.gz
In the preceding example, output from dump was sent to stdout and piped to the gzip program to be compressed. If your tape doesn't provide hardware compression, using the preceding command can be an effective way of increasing tape capacity.
For complete information on the myriad of options that dump provides, read your system's documentation.
To extract files backed up with dump, use restore. restore copies files stored in a dump tape or file to the current directory. Note that using restore can and will clobber exiting files with matching names. restore will also create any directories or directory trees that it needs before extracting a file. This feature is powerful if you know what you are doing. If in doubt, restore to an empty directory and move the files by hand. restore has the following syntax:
/usr/etc/restore [options [argument ]]
By default, restore will use the tape drive at /dev/rxt0 (check your man page). If you want to override this device, use the f option.
restore has an easy-to-use interactive shell-like interface that allows you to navigate through the dump tape as if your were in a filesystem. The interactive session is started by using the i option.
To restore all files from a tape, use this:
restore r
To restore a particular file, use this:
restore x /Users/demo/file.rtf
The preceding command will extract (x) the file specified (/Users/demo/file.rtf) from the tape. If the directories don't exist, it will create them. It's a good idea to direct restore to put recovered files on an empty directory, and then move the files to their final destination.
To restore from a compressed gzip archive, use this:
gzcat /tmp/backup.gz | restore f -
To create a catalog from files on a dump tape, use the t option. It is always a good idea to create a catalog from your tape. This will ensure that the backup tape you made contains the correct information and that the tape is readable.
Listing 4.1 is a script I use to automate backups. It is called from cron (see your UNIX documentation) with the level for the backup. Customizing it to fit your needs should not be very hard. Just read over all the options and make sure that the commands in your system are located in the same place. Also verify that the /dev files I reference match your configuration and change accordingly. This script automatically creates a catalog of the backups; it will also send a message notifying you if the backup was successful.
Listing 4.1. An automated backup script.
#!/bin/csh -f
# Simple backup csh program. Takes one argument, the dump level.
# The goal of a backup is not only to save the data in case of disaster,
# but to minimize the time and grief required to get the system
# running again...
# cAlberto Ricart, 7/1/1996
#
# This example backups 2 disks /dev/rsd1a and /dev/rsd0a, in order of preference.
# /dev/rsd1a contains a lot of user data, if the tape were to fill up in the
# middle of
# the second backup, we are assured that the important data copied OK.
# as a peace of mind, this script generates a listing of all the files. This is
# just
# a test to verify that the tape can be read. Also helpful for locating files.
# Please verify that these commands have the same significance as yours.
# Also, more than likely you'll have to change the /dev/rsd1a and /dev/rsd0a to
# point to
# your raw disk device, as well as your tape device /dev/nrxt0 on our case.
set LOGGER = '/usr/ucb/Mail '
set DUMP_LOG = '/usr/local/adm/dump.log'
set DUMP = '/usr/etc/dump'
set DUMP_ARGS = ''$1'ufs /dev/nrxt0 1200000'
set GZIP = '/usr/bin/gzip -9'
set RM = '/bin/rm'
set TAPE = '/bin/mt -f /dev/nrxt0'
set PRINTCAT = '/usr/etc/restore t'
set CATDIR = '/usr/local/amd/Tape_Catalogs'
set DATE = `/bin/date | /bin/awk '{print $1":"$2":"$3":"$6 }'`
set OPERATOR = 'webmaster'
if ($#argv == 1) then
$DUMP $DUMP_ARGS /dev/rsd1a |& $LOGGER $DUMP_LOG || mail -s DISK1_ BACKUP_FAILED $OPERATOR
$DUMP $DUMP_ARGS /dev/rsd0a |& $LOGGER $DUMP_LOG || mail -s DISK0_ BACKUP_FAILED $OPERATOR
$TAPE rewind
$PRINTCAT > $CATDIR/$DATE.rsd1a.dump.$1
$TAPE fsf 1
$PRINTCAT > $CATDIR/$DATE.rsd0a.dump.$1
$TAPE rewind
mail -s BACKUP_OK $OPERATOR
exit (0)
else
echo "Backup script had no dump level, aborting" | mail -s BACKUP_ ABORTED $OPERATOR
exit (1)
endif
exit (1)
UNIX provides tools for monitoring your disk space as well as for monitoring the load incurred by your disk: df and iostat, respectively.
df (disk free) displays various statistics regarding all currently mounted disks on your system. It reports on capacity, used amount, and free amount, in kilobytes and percentage formats:
% df Filesytem kbytes used avail capacity Mounted on /dev/sd0a 1014845 397882 515478 44% / /dev/sd0b 1014845 329337 584023 36% /usr/local
iostat displays information about disk performance, including the number of characters read and written to terminals for each disk, the number of transfers per second, and other information.
From this information you can glean the load affecting your disks:
% iostat tty sd0 cpu tin tout bps tps msps us ni sy id 0 6 80 14 0.5 2 0 5 93
One of the main reasons to monitor disk space is because if the logs are not checked periodically, they will fill up your filesystem. You should monitor what's in logs as well as the size of the logs.
If there's one thing that logs do, it's grow. The bigger they are, the longer it takes to process them. Organizing and managing your logs is a good thing to do because it provides you with a systematic way of naming and storing the logs. Once the logs are properly named, you can dump them to tape and forget about them. Should you ever need them, you can quickly retrieve them.
Small sites may not need their logs rotated more often than once a month. Heavy-traffic systems should really consider not logging at all. However, if logging is absolutely necessary, resetting the logs on a daily basis can produce a more manageable logfile.
To give you an idea of how quickly logs grow, the typical access log entry contains 85 bytes per request. Not much. However, on a site that handles 5 million requests a day at 85 bytes per request, this translates into 405MB of log data per day! You should rotate logs at an interval that gives you a manageable file size.
Resetting logs is a bit tricky. Apache won't start logging on to a new file until it restarts. The easiest way to accomplish the rotation is through a script that renames the logfile and then sends the server a HUP (hangup) signal. However, the problem with this approach is that all the current connections to the server will be terminated.
A simple script is shown in Listing 4.2.
Listing 4.2. Resetting the logfile.
# This scrip resets the log file, the log is renamed with todays date
# c1996 Alberto Ricart
# This script asumes that the PID file exists in its default location
# Bugs: Should handle a list of filenames, instead of just one.
#
set OPERATOR = 'webmaster'
set DATE = `/bin/date | /bin/awk '{print $1":"$2":"$3":"$6 }'`
if ($#argv == 1) then
if (-e $1) then
mv $1 $1$DATE.weblog
kill -HUP 'cat /usr/local/etc/httpd/logs/apache.pid'
exit (0)
else
echo "Logfile $1 doesn't exist." | mail -s LOG_ROTATION_ABORTED $OPERATOR
exit 1
endif
else
echo "You didn't provide a path to a log file." | mail -s LOG_ROTATION_ ABORTED $OPERATOR
exit 1
endif
exit 0
Apache 1.1 ships with a utility program called rotatelogs that can be used to automatically reset the log without having to stop the server. As a side benefit, the program also names files incrementally.
To use rotatelogs, you'll need to compile it. You can do this easily by issuing the following commands:
cd /usr/local/etc/httpd/support cc -o rotatelogs rotatelogs.c strip rotatelogs
After a few moments, the program rotatelogs will be built. Next, you'll need to specify that output to the logfiles should be redirected to rotatelogs. The rotatelogs program uses the following syntax:
rotatelogs logfilename time
Where logfilename is the path to a logfile. logfilename will be used as the base name for the log. It's followed by a number that represents the system time. A new logfile will be started at the end of time. time specifies the rotation time in seconds.
To rotate the access and error logs every 24 hours, you'll need to modify the TransferLog and ErrorLog directives in your httpd.conf file like this:
TransferLog "|/usr/local/etc/httpd/support/rotatelogs /usr/local/etc/httpd/logs/access_log 86400" ErrorLog "|/usr/local/etc/httpd/support/rotatelogs /usr/local/etc/httpd/logs/error_log 86400"
Upgrades are always a cause for concern in production environments. The overall strategy should be to install any new versions of the server in a test environment prior to putting the server into production. Always read the distribution documentation to see if some behavior has changed from previous versions.
To be on the safe side, you should keep an old version of the server on hand just in case the new one causes some problems. An easy way to do this is to install the new server after you rename the old one to httpd.old, and restart the server. If you discover any problems, you can quickly put the old server back online by renaming httpd.old to httpd and restarting the server again.
One of the biggest concerns you'll have is making sure that your machines are working correctly. Automated periodic testing of your site can help you ensure that it is accessible. A good setup has internal and external testing systems.
The best type of testing is actually the type that you don't have to do. For a small fee, some companies monitor your site every few minutes. If there's a problem, they call your beeper and inform you that something is afoot. They even go so far as making sure that your Web page is accessible. One such service can be found at http://www.redalert.com.
Having an external source test the accessibility of your Web site is a great idea because it confirms to your customers that users are able to access your site. You will know within a reasonable amount of time if your network becomes unreachable because of a problem with your provider.
The easiest way for you to test whether your server is reachable is to use the ping command. The ping command will send an ECHO_REQUEST datagram to a host or network interface. On reception, the packet is returned with an ECHO_RESPONSE datagram. While this test does not verify that your server is operating correctly, it does verify that the networking portion of it is reachable.
The format of the command is
/etc/ping ipaddress packetsize pingcount
Typically, you will want to use the ping command to send a datagram to the host to verify that your network interface is running. Once this is verified, you can start test from other hosts and gateways farther away.
When you monitor HTTP, you ensure that the server is running and you assess its current load. Apache has implemented a series of child processes that are semipersistent. Unlike some servers, which fork a new server process with each request and then kill off the new process as the request is satisfied, Apache implements a system that tracks all idle and busy server processes. If more server processes are needed, it creates more to handle the load (up to a limit). If the count of idle server processes exceeds a certain amount, the extra httpd processes are killed. This avoids a condition in which too many server processes compete for resources and effectively kill the machine. If the machine starts swapping, it becomes unusable and it is brought to its knees.
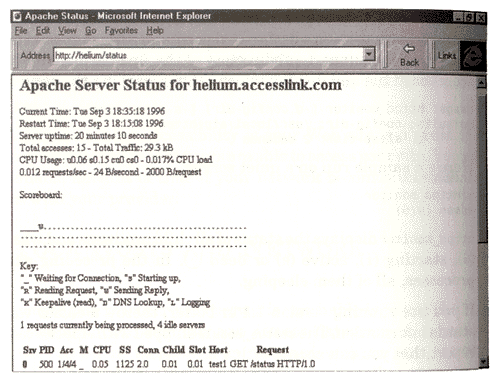
Apache's server implementation makes it harder to ascertain the current status of the server. To circumvent this problem, Apache has implemented a scoreboard status file. The scoreboard file allows all the various server processes to write status information on a designated portion of a file. A special program, httpd_monitor, located in the support subdirectory of the Apache distribution, is able to read the scoreboard file and display information regarding the server:
Usage: httpd_monitor [-d config-dir] [-s sleep-time] Defaults: config-dir: /usr/local/etc/httpd/ sleep-time: 2 seconds
Here's a sample run on a quiet server:
% httpd_monitor sssss (0/5)
httpd_monitor displays the status of all child processes and whether they are sleeping (s), starting (t), active (R) or dead (_). In the preceding example, there are five processes, all of them sleeping.
If you are running version 1.1 or better, there's a easier way of obtaining server status information. The status_module shipped with Apache can display a nice HTML report that you can access with a browser.
To enable this module, just uncomment the following line from your src/Configuration file:
Module status_module mod_status.o
For more descriptive status reports, also add the -DSTATUS flag to the CFLAGS section near the start of the file. Build and install the new version of Apache by issuing the following commands:
cd /usr/local/etc/httpd/src ./Configure make strip httpd mv httpd ../
In addition to building the new program, you'll have to edit your conf/access.conf file and add an entry like this one:
<Location /status> SetHandler server-status order deny,allow deny from all allow from yourdomain </Location>
Change yourdomain to your Internet domain. As you should be able to tell from this configuration, the server will only supply status information to requests that originate within your domain name. Once the server is restarted, a request for the for /status on your server (http://www/status) will return a nicely formatted report.
Fig. 11.1 A server status report generated by the staus_module.
You can have the status information (produced by the status_module) updated every few seconds by calling typing
http://your.server.name/status/?refresh=N
Replace N with the number of seconds between updates.
In addition, you can access a machine-readable ASCII version of the report by requesting:
http://your.server.name/status/?auto
The Berkeley Internet Name Domain (BIND) system includes a utility called name daemon control (ndc) interface, which allows you to easily send various signals to the name server. It also allows you to start, restart, or stop the name server. Even better, it allows you to display many status settings, as well as display cache and query log information. For extensive information on what a name server does, see Appendix E, "DNS and BIND Primer."
To check if your name server is running, just enter the following commands on a shell:
% ndc status 3170 ? SW 0:00 named
This displays a short line with process-status information.
From this line I know that my process is running, sleeping, and swapped out of memory. For more information on what this output means, check out the man page for ps.
If your server was not running, it would display a line such as this:
named (no pid file) not running
or this:
named (pid 3262?) not running
A better way to monitor the name server is to look at the logfiles. named uses the syslog facility to log problems. To see where syslog logs named messages, run this command:
grep daemon /etc/syslog.conf
Check the lines that contain named. An easy way to do this is to do a grep on named. It should be obvious when the problem is due to an incorrectly defined dbfile because named should echo a descriptive message to this effect. It is important to look for these errors because some of them may lead to your server stopping. An unreachable message can result in a secondary name server declaring that the data is stale and refusing to serve it. malformed type errors usually mean that some server provided a malformed response.
The worst thing that could happen (besides your processor catching fire) is that your domain name server stops running. If the DNS goes, your network grinds to a halt. External users will be unable to reach it, and internal users will be unable contact external resources.
There are several solutions to this problem:
This chapter covers some basic system administration points as they relate to the management of your Web site. Preventive action in terms of backups and the monitoring of processes and resources signal issues before they become a problem. The tools covered in this chapter are universally available to most unices. Commercial products are also available that address network monitoring. However, these tools are costly; some of the most popular tools cost thousands of dollars.
An inexpensive, efficient way to automate the generation of the server and network status information is by having a Web page that summarizes the information from the commands described in this chapter. When used under cron, you can ensure systematic testing of the various systems.
{kind=link}